Apache Kudu support in Apache Apex
Introduction
The last few years has seen HDFS as a great enabler that would help organizations store extremely large amounts of data on commodity hardware. However over the last couple of years the technology landscape changed rapidly and new age engines like Apache Spark, Apache Apex and Apache Flink have started enabling more powerful use cases on a distributed data store paradigm. This has quickly brought out the short-comings of an immutable data store. The primary short comings are:
- Immutability resulted in complex lambda architectures when HDFS is used as a store by a query engine
- When data files had to be generated in time bound windows data pipeline frameworks resulted in creating files which are very small in size. Over a period of time this resulted in very small sized files in very large numbers eating up the namenode namespaces to a very great extent.
- With the arrival of SQL-on-Hadoop in a big way and the introduction new age SQL engines like Impala, ETL pipelines resulted in choosing columnar oriented formats albeit with a penalty of accumulating data for a while to gain advantages of the columnar format storage on disk. This reduced the impact of “information now” approach for a hadoop eco system based solution.
Apache Kudu is a next generation storage engine that comes with the following strong points
- A distributed store
- No single point of failure by adopting the RAFT consensus algorithm under the hood
- Mutable
- Auto compaction of data sets
- Columnar storage model wrapped over a simple CRUD style API
- Tabular structure as a storage model
- Bulk scan patterns possible
- Predicate push downs when scanning
This post explores the capabilties of Apache Kudu in conjunction with the Apex streaming engine. Apache Apex is a low latency distributed streaming engine which can run on top of YARN and provides many enterprise grade features out of the box. The post describes the features using a hypothetical use case. The use case is of banking transactions that are processed by a streaming engine and then to need to be written to a data store and subsequently avaiable for a read pattern. The caveat is that the write path needs to be completed in sub-second time windows and read paths should be available within sub-second time frames once the data is written.
Apex integration
Apache Apex integration with Apache Kudu is released as part of the Apache Malhar library. Apache Malhar is a library of operators that are compatible with Apache Apex. Kudu integration in Apex is available from the 3.8.0 release of Apache Malhar library.
An Apex Operator ( A JVM instance that makes up the Streaming DAG application ) is a logical unit that provides a specific piece of functionality. In the case of Kudu integration, Apex provided for two types of operators
- A write path is implemented by the Kudu Output operator
- A read path is implemented by the Kudu Input Operator.
Apex uses the 1.5.0 version of the java client driver of Kudu. A sample representation of the DAG can be depicted as follows:
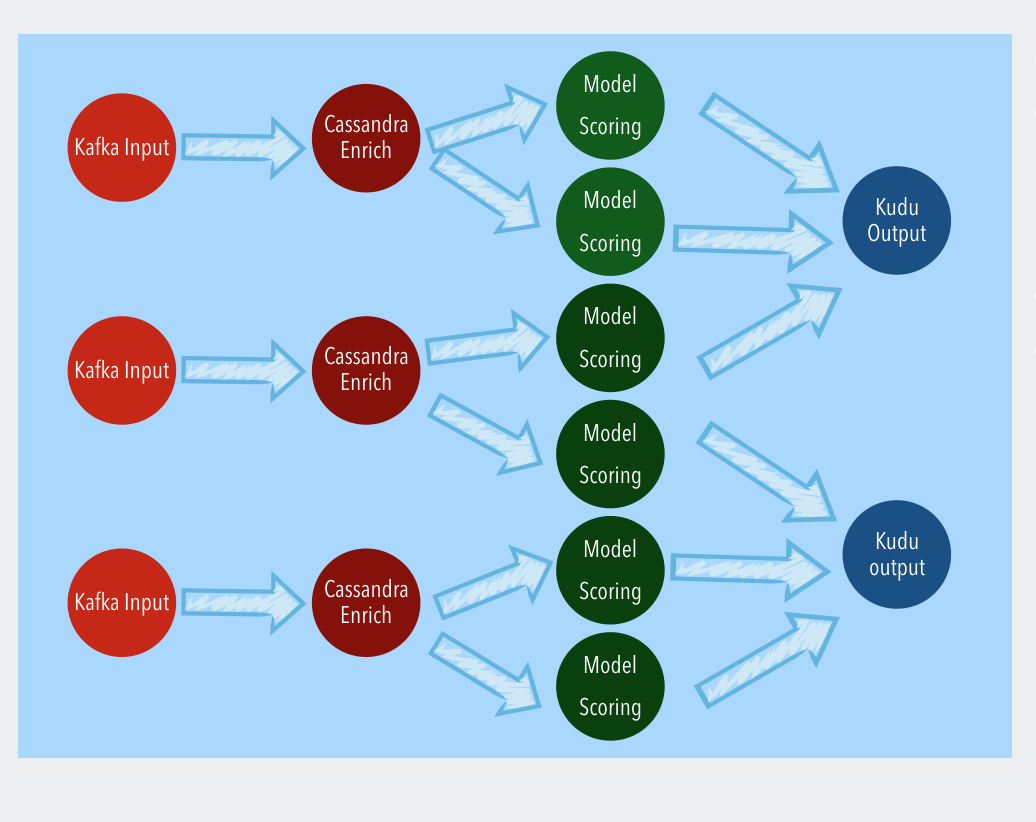
Write paths
In our example, transactions( rows of data) are processed by Apex engine for fraud. As soon as the fraud score is generated by the Apex engine, the row needs to be persisted into a Kudu table. The following are the main features supported by the Apache Apex integration with Apache Kudu.
Write modes at a tuple level
The kudu outout operator allows for writes to happen to be defined at a tuple level. The following modes are supported of every tuple that is written to a Kudu table by the Apex engine.
- Insert
- Update
- Upsert
- Delete
Automatic mapping to Kudu table column names
Kudu output operator uses the Kudu java driver to obtain the metadata of the Kudu table. By using the metadata API, Kudu output operator allows for automatic mapping of a POJO field name to the Kudu table column name. Of course this mapping can be manually overridden when creating a new instance of the Kudu output operator in the Apex application
Multiple table writes
The Kudu output operator allows for writing to multiple tables as part of the Apex application. This can be achieved by creating an additional instance of the Kudu output operator and configuring it for the second Kudu table. For example, a simple JSON entry from the Apex Kafka Input operator can result in a row in both the transaction Kudu table and the device info Kudu table.
Selective column writes
Kudu output operator also allows for only writing a subset of columns for a given Kudu table row. This optimization allows for writing select columns without performing a read of the current column thus allowing for higher throughput for writes.
For example, in the device info table as part of the fraud processing application, we could choose to write only the “last seen” column and avoid a read of the entire row.
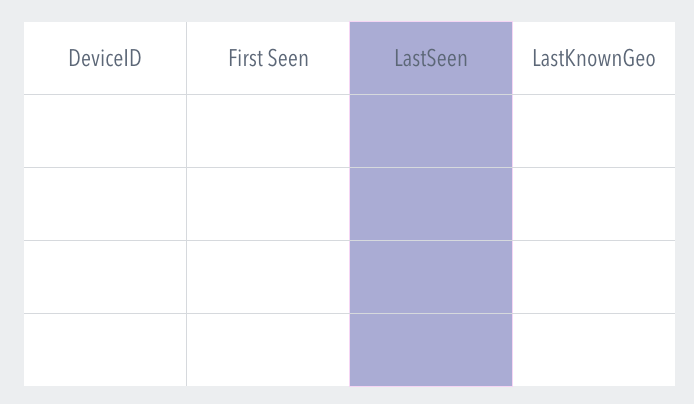
End to end exactly once semantics
Kudu output operator allows for end to end exactly once processing. Since Kudu does not yet support bulk operations as a single transaction, Apex achieves end ot end exactly once using the windowing semantics of Apex. Apex Kudu output operator checkpoints its state at regular time intervals (configurable) and this allows for bypassing duplicate transactions beyond a certain window in the downstream operators. For the case of detecting duplicates ( after resumption from an application crash) in the replay window, Kudu output operator invokes a call back provided by the application developer so that business logic dictates the detection of duplicates. The business logic can invole inspecting the given row in Kudu table to see if this is already written. Note that this business logic is only invoked for the application window that comes first after the resumption from a previous application shutdown or crash.
Setting write timestamps
Kudu output operator allows for a setting a timestamp for every write to the Kudu table. This feature can be used to build causal relationships. For example, we could ensure that all the data that is read by a different thread sees data in a consistent ordered way.
Metrics
Kudu output operator utilizes the metrics as provided by the java driver for Kudu table. Some of the example metrics that are exposed by the kudu output operator are bytes written, RPC errors, write operations. There are other metrics that are exposed at the application level like number of inserts, deletes , upserts and updates. Note that these metrics are exposed via the REST API both at a single operator level and also at the application level (sum across all the operator instances)
Read paths
Apex Kudu integration also provides the functionality of reading from a Kudu table and streaming one row of the table as one POJO to the downstream operators. The read operation is performed by instances of the Kudu Input operator ( An operator that can provide input to the Apex application). The following use cases are supported by the Kudu Input operator in Apex.
SQL driven scans
The Kudu input operator can consume a string which represents a SQL expression and scans the Kudu table accordingly. The SQL expression is not strictly aligned to ANSI-SQL as not all of the SQL expressions are supported by Kudu. However the Kudu SQL is intuitive enough and closely mimics the SQL standards. The SQL expression should be compliant with the ANTLR4 grammar as given here
Distributed scans
The Kudu input operator heavily uses the features provided by the Kudu client drivers to plan and execute the SQL expression as a distributed processing query. At the launch of the Kudu input operator JVM, all the physical instances of the Kudu input operator agree mutually to share a part of the Kudu partitions space. This is transparent to the end user who is providing the stream of SQL expressions that need to be scanned and sent to the downstream operators.
High throughput read scans
Since Kudu is a highly optimized scanning engine, the Apex Kudu input operator tries to maximize the throughput between a scan thread that is reading from the Kudu partition and the buffer that is being consumed by the Apex engine to stream the rows downstream. The Kudu input operator makes use of the Disruptor queue pattern to achieve this throughput.
Partition mapping
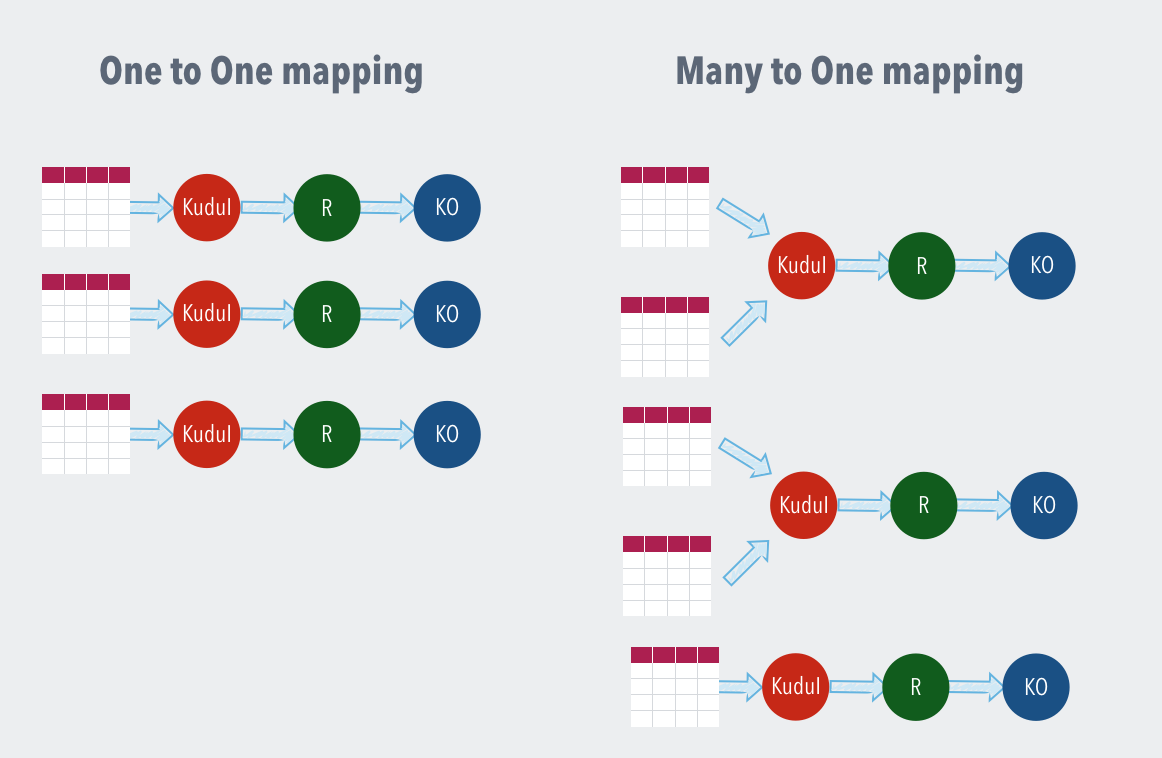
Kudu allows for a partitioning construct to optimize on the distributed and high availability patterns that are required for a modern storage engine. Apex also allows for a partitioning construct using which stream processing can also be partitioned. Kudu input operator allows for mapping Kudu partitions to Apex partitions using a configuration switch. While Kudu partition count is generally decided at the time of Kudu table definition time, Apex partition count can be specified either at application launch time or at run time using the Apex client. Kudu input operator allows for two types of partition mapping from Kudu to Apex.
- One to One mapping ( maps one Kudu tablet to one Apex partition )
- Many to One mapping ( maps multiple Kudu tablets to one Apex partition )
This can be depicted in the following way.
Kudu high availability
Kudu client driver provides for a mechanism wherein the client thread can monitor tablet liveness and choose to scan the remaining scan operations from a highly available replica in case there is a fault with the primary replica. Opting for a fault tolerancy on the kudu client thread however results in a lower throughput. Hence this is provided as a configuration switch in the Kudu input operator. Kudu fault tolerant scans can be depicted as follows ( Blue tablet portions represent the replicas ):
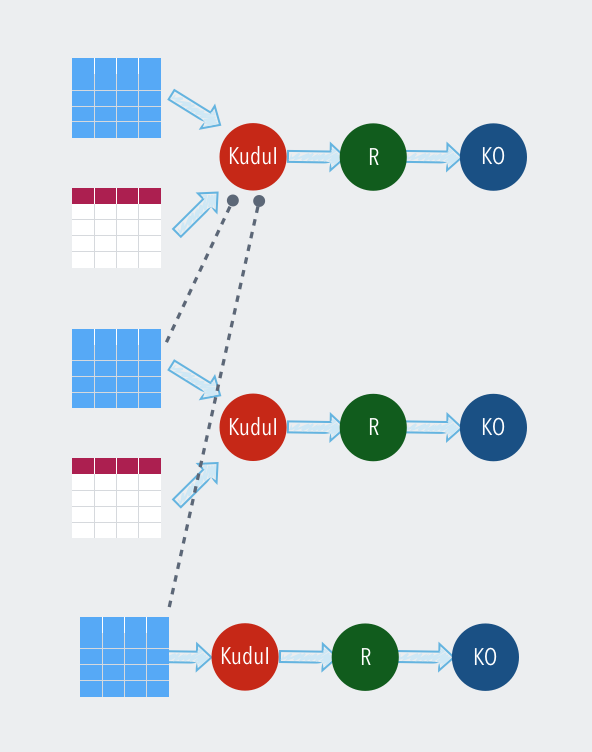
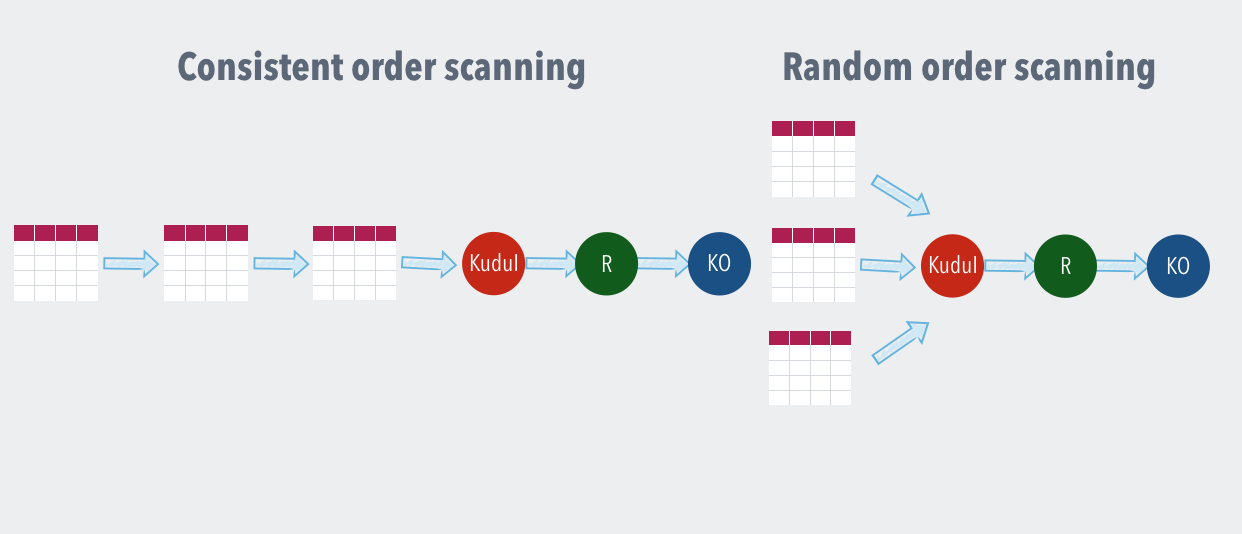
Scan order
Kudu input operator allows for a configuration switch that allows for two types of ordering. The ordering refers to a guarantee that the order of tuples processed as a stream is same across application restarts and crashes provided Kudu table itself did not mutate in the mean time. This feature allows for implementing end to end exactly once processing semantics in an Apex appliaction. There are two types of ordering available as part of the Kudu Input operator.
- Consistent ordering : This mode automatically uses a fault tolerant scanner approach while reading from Kudu tablets. This also means that consistent ordering results in lower throughput as compared to the random order scanning
- Random ordering : This mode optimizes for throughput and might result in complex implementations if exactly once semantics are to be achieved in the downstream operators of a DAG.
The scan orders can be depicted as follows:
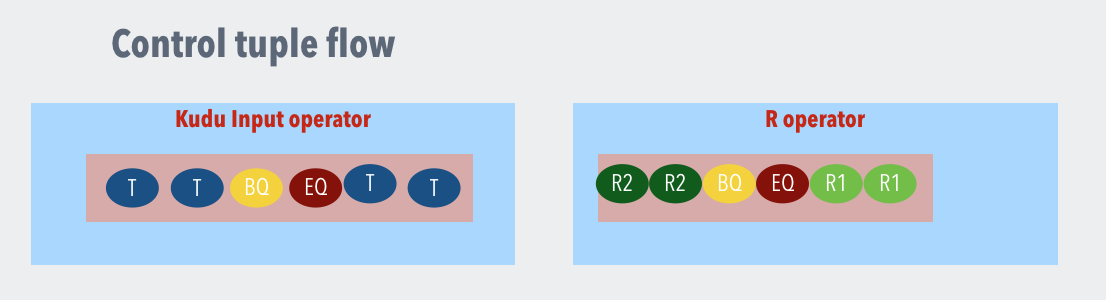
Control tuples
Kudu input operator allows users to specify a stream of SQL queries. Each operator processes the stream queries independent of the other instances of the operator. This essentially implies that it is possible that at any given instant of time, there might be more than one query that is being processed in the DAG. To allow for the down stream operators to detect the end of an SQL expression processing and the beginning of the next SQL expression, Kudu input operator can optionally send custom control tuples to the downstream operators. The SQL expression supplied to the Kudu input oerator allows a string message to be sent as a control tuple message payload. The user can extend the base control tuple message class if more functionality is needed from the control tuple message perspective. The control tuple can be depicted as follows in a stream of tuples. In the pictorial representation below, the Kudu input operator is streaming an end query control tuple denoted by EQ , then followed by a begin query denoted by BQ. These control tuples are then being used by a downstream operator say R operator for example to use another R model for the second query data set.
Time travelling in Kudu
Another interesting feature of the Kudu storage engine is that it is an MVCC engine for data!!. This essentially means that data mutations are being versioned within Kudu engine. This allows for some very interesting feature set provided of course if Kudu engine is configured for requisite versions. If the kudu client driver sets the read snapshot time while intiating a scan , Kudu engine serves the version of the data at that point in time. Kudu input operator allows for time travel reads by allowing an “using options” clause. One of the options that is supported as part of the SQL expression is the “READ_SNAPSHOT_TIME”. By specifying the read snapshot time, Kudu Input operator can perform time travel reads as well. An example SQL expression making use of the read snapshot time is given below.
select col1,col2 from kudutable where col3 > 345 using options READ_SNAPSHOT_TIME=1507601194
Conclusion
Thus the feature set offered by the Kudu client drivers help in implementing very rich data processing patterns in new stream processing engines. The feature set of Kudu will thus enable some very strong use cases in years to come for:
- SQL on hadoop engines like Impala to use it as a mutable store and rapidly simplify ETL pipelines and data serving capabilties in sub-second processing times both for ingest and serve.
- Streaming engines able to perform SQL processing as a high level API and also a bulk scan patterns
- As an alternative to Kafka log stores wherein requirements arise for selective streaming ( ex: SQL expression based streaming ) as opposed to log based streaming for downstream consumers of information feeds
- Simplification of ETL pipelines in an Enterprise and thus concentrate on more higher value data processing needs.
Kudu integration with Apex was presented in Dataworks Summit Sydney 2017. A copy of the slides can be accessed from here